Back to All Research Articles
⚖️ Fair and Explainable Credit-Scoring under Concept Drift: Adaptive Explanation Frameworks for Evolving
Populations
This research explores how AI credit-scoring models can stay fair, transparent, and reliable over time even
as customer behavior, economics, or demographics change. It introduces an adaptive explanation framework
that monitors how model decisions evolve, detects data or concept drift, and ensures that explanations
remain stable and fair across groups like gender, income, or region. Using metrics for drift detection,
fairness auditing, and explainability stability (such as cosine similarity, Kendall tau, and Jaccard
overlap), the study builds a foundation for ethical and trustworthy AI in financial decision-making. Beyond
credit scoring, the framework applies to any industry using predictive models from insurance and healthcare
to retail helping organizations balance accuracy, fairness, and accountability while maintaining regulatory
compliance and public trust.
📈 Business Impact, Profitability & Real World Deployment
💰 Business Impact and Profitability
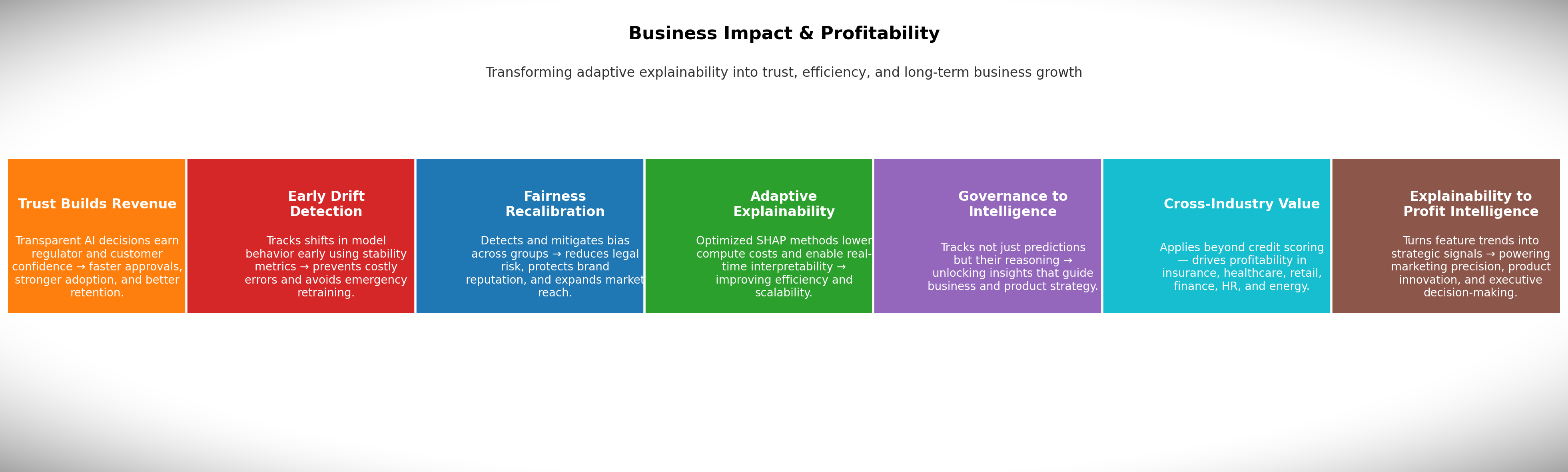
This research bridges responsible AI and business performance by showing how adaptive explainability can
directly improve trust, reduce risk, and enhance profit across industries not just in credit scoring.
- Trust Builds Revenue
When people and regulators understand
why an AI made a decision, they trust it. This trust accelerates regulatory approval, increases customer
adoption, and reduces complaints. For example, a lender that clearly explains credit decisions sees
higher customer retention and faster market entry.
- Early Drift Detection Prevents Losses
The system tracks
changes in model behavior over time using advanced stability metrics. This allows early detection when
models start making unusual or biased decisions before they cause financial damage. By catching drift
early, businesses avoid costly retraining, poor loan approvals, or pricing mistakes.
- Fairness Recalibration Reduces Risk
The framework identifies
and corrects potential biases related to race, gender, or income. This reduces legal exposure, avoids
regulatory fines, and strengthens brand reputation. Fair models also expand customer eligibility
ethically increasing approved users and market reach.
- Adaptive Explainability Saves Costs
Traditional
explainability methods are computationally heavy. The adaptive SHAP framework introduced here updates
explanations more efficiently, cutting cloud costs and enabling real-time interpretability. This reduces
infrastructure spending while maintaining transparency at scale.
- Smarter Governance, Stronger Strategy
The system doesn’t
just explain predictions it tracks how feature importance changes over time. That historical insight
becomes a form of business intelligence. Teams can learn what drives customer behavior, optimize
decisions, and even discover new product opportunities from evolving patterns.
- Beyond Credit Scoring
The framework applies across
industries:
- Insurance: Detect fraud more accurately and reduce
false investigations.
- Healthcare: Increase doctor trust in AI diagnoses and
meet compliance standards.
- Retail: Improve demand forecasting and marketing ROI
through interpretable models.
- Finance: Prevent model drift in trading or risk models
to avoid losses.
- HR: Detect and mitigate bias in hiring systems.
- Energy: Adapt predictions under changing environmental
or market conditions.
- Turning Explainability into Competitive
Intelligence
Explainability data reveals why customers behave a certain way. Businesses
can use that knowledge to tailor marketing, design better products, and make faster strategic decisions.
This transforms explainability from a compliance necessity into a driver of innovation and profit.
In essence: Fair, explainable, and adaptive AI isn’t just ethical it’s
profitable. It lowers operational costs, prevents failures, builds trust, and converts
transparency into long-term business value.
🚀 Real-World Deployment
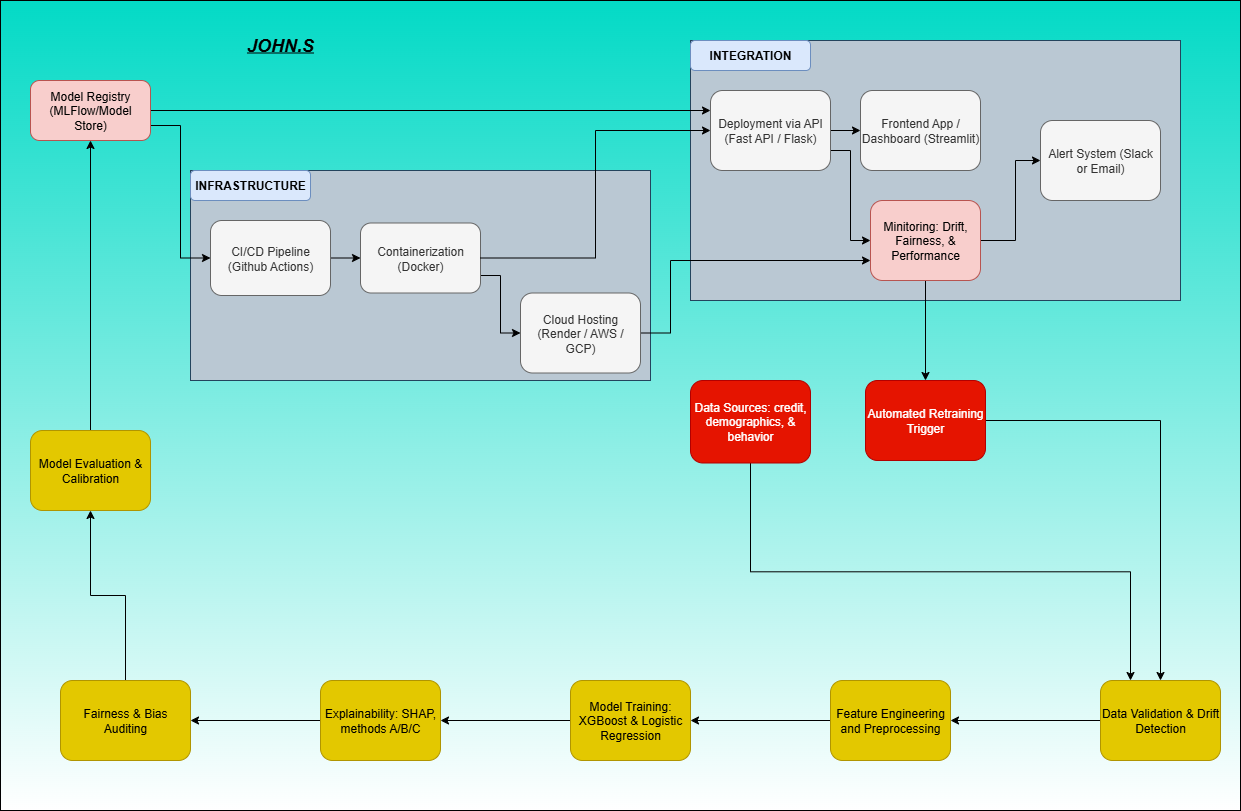
- Data Ingestion & Monitoring
Pulls data continuously from
internal systems (loan applications, transactions, user profiles, etc.). Validates schema and detects
missing or drifted features using PSI, KS, and JS Divergence metrics. Sends drift alerts to a monitoring
dashboard (e.g., Prometheus + Grafana).
- Preprocessing & Feature Store
Uses a centralized Feature
Store (like Feast or Vertex AI) for consistent features across training and inference. Stores engineered
features such as age buckets, income levels, and behavior indicators. Pipelines built in scikit-learn or
PySpark automatically version features and handle scaling/imputation.
- Model Training & Validation
Uses scheduled retraining
(weekly/monthly) triggered by drift or performance degradation. Employs cross-validation, SMOTE for
class balance, and automatic hyperparameter tuning. Logs all metrics (ROC-AUC, F1, fairness metrics) to
MLflow or Weights & Biases for traceability.
- Fairness & Explainability Audits
Post-training audit layer
runs fairness checks across sensitive attributes (race, gender, income). Generates SHAP-based
explainability reports and stability comparisons across time. Results are pushed to a compliance
dashboard for internal or regulatory review.
- Model Registry & Versioning
Trained models are stored in a
Model Registry (MLflow / Sagemaker Model Registry). Each model version includes metadata: dataset hash,
drift metrics, fairness report, and SHAP plots. Only validated and bias-free versions are promoted to
production.
- Deployment & Serving
Models deployed via RESTful APIs or
containerized microservices (Docker + Kubernetes). Real-time inference handled by a scalable prediction
service (e.g., FastAPI + Redis queue). Each prediction logs input, output, and explanation for
traceability.
- Continuous Monitoring & Retraining Loop
Monitors prediction
accuracy, fairness drift, and SHAP stability in production. If drift or bias exceeds threshold triggers
automatic retraining and redeployment. Alerts routed through Slack, Opsgenie, or email for human review
before rollout.
- Security & Compliance Layer
Data encrypted at rest (S3, GCS)
and in transit (TLS). Access controls managed via IAM and audit trails. Ensures explainability and
fairness logs align with AI governance and regulatory standards (e.g., GDPR, CFPB, ISO/IEC 42001).
Outcome: This pipeline ensures the system stays fair, explainable,
and stable in real-world use detecting drift early, maintaining trust with regulators and users, and
enabling continuous, ethical AI at scale.
